# Synchronization Operating Systems 2 Lecture <small>Warsaw University of Technology<br/>Faculty of Mathematics and Information Science</small> --- ## Part 0 The Classical Critical Section Problem (Theory) --- ### Problem Illustration Consider multiple processes, each having a code section touching same set of shared variables (same memory locations). ```cpp int balances[MAX_ACCOUNTS]; // Global shared data structure // Server process routine while (true) { int fd = wait_for_client(); if (fd < 0) { /* ERR */ } struct request req = read_request(fd); // Shared data access transfer(balances, req.src, req.dst, req.amount); close(fd); } ``` --- Consider the following `transfer()` implementation: ```c int transfer(int* balances, int src, int dst, int amount) { if (balances[src] < amount) { return -1; } balances[src] -= amount; balances[dst] += amount; return 0; } ``` Is it safe to run concurrently? --- Imagine two processes/threads have received a request to `transfer()` <br> 100 _money_ from account `3` to `9` when initially `balances[3] = 120`. ```text T ----------- P101 ----------- ----------- P102 ----------- 0 if (balances[src] < amount) 1 if (balances[src] < amount) 2 balances[src] -= amount; 3 balances[src] -= amount; 4 balances[dst] += amount; 5 balances[dst] += amount; 6 return 0; 7 return 0; ``` At `T=3` bad things happen: balance of source account drops below 0. The server needs to ensure that _only one thread at any time point executes_ `transfer()`. --- ### Problem Definition Ensuring something some memory area is accessed by at most one CPU is a very common concern in concurrent systems, known as **critical section problem**. ```c while (true) { /* 1. ENTRY SECTION */ wait_for_access(); /* 2. CRITICAL SECTION (CS) */ access_shared_data(); /* 3. EXIT SECTION */ release_access(); /* 4. REMAINDER SECTION */ do_other_unrelated_work(); } ``` Solving the problem = providing **correct** implementations of entry and exit. --- ### What correct means? Any valid solution must satisfy three conditions: 1. **Mutual Exclusion:** At most one process can be inside the CS at any given time. 2. **Progress:** If the CS is free, and some processes are waiting in the entry section, one will eventually enter. Decision may not be postponed indefinitely. 3. **Bounded Waiting:** When some process enters entry section it start counting number of times others have entered CS. A bound must exist for this counter. Consider why 1. or 1. & 2. are not enough. --- ### Solution Attempt 1 Let's grant access conditionally, based on shared boolean variable: ```c int flag = 0; while (true) { while (flag) { /* busy wait */ } flag = 1; critical_section(); flag = 0; remainder_section(); } ``` This solution fails to satisfy **Mutual exclusion** property. --- ### Solution Attempt 2 If one flag is not enough, maybe two would suffice. Each process "raises a hand" when it wants to enter. ```c int flag[2] = {0, 0}; while (true) { flag[i] = 1; // `i` is a process number - 0 or 1 while (flag[1 - i]) { /* busy wait */ } critical_section(); flag[i] = false; remainder_section(); } ``` This one provides mutual exclusion but lacks **Progress**! We need to somehow break the `while` and select one of the waiting processes. --- ### Mutual exclusion  --- ### Peterson's Algorithm (1981) Adds a single, decision variable called `turn`: ```c int flag[2] = {0, 0}; int turn = 0; while (true) { flag[i] = 1; // `i` is a process number - 0 or 1 turn = 1 - i; while (flag[1 - i] && turn == 1 - i) { /* busy wait */ } critical_section(); flag[i] = false; remainder_section(); } ``` * Satisfies all 3 correctness conditions. * The theoretical Holy Grail of two-process synchronization. * **It sadly fails when naively coded in C** --- ### Mutual exclusion Case 1: Second enters after reading opposite flag = 0  --- ### Mutual exclusion Case 2: Second enters after reading turn = me  --- ### Progress and bounded waiting **Progress** holds as processes cannot spin in the `while` loops indefinitely. `turn` cannot be both `0` and `1` at the same time. **Bounded waiting** holds since if process `Pi` already waits in `while` the other one can't enter first, even if it would extremely fast reach its `while` again. --- ## Part 1 **Hard**ware Reality vs. Theory --- ## CPU communication The solution to the problem of touching the shared concurrently data was touching some (other) shared data itself! That's the only option we have: inter CPU core communication is possible through the main memory only!  --- ## The old assumptions Peterson's solution assumes: - solution's code is literally translated to machine instructions, preserving source operation order - reads and writes of shared integers are **atomic** - cores reading concurrently written values may not observe partly updated value - they read either value before the change or fully overwritten - **consistent ordering** of memory operations - when one core writes `a` and then `b`, others observe changes in exactly the same order On modern platforms none of this is true! To make any synchronization algorithm work we need to overcome all of these. --- ### Compilation process Compiler does not translate code literally. It must generate code which does the computation expressed in the source. ```c int data = 0; int ready = 0; void th1() { data = 42; // Operacja A ready = 1; // Operacja B } int th2() { while (ready == 0) { // Aktywne czekanie (busy-wait) - Operacja C } return data; // Operacja D } ``` See in the [compiler explorer](https://godbolt.org/z/9cnndKPn6) --- ### Compiler freedom Compiler may do anything as long as **observable effects** of the single threaded execution stay unchanged. * Cache variables in registers instead of constantly polling RAM in `while` loops * Remove instructions entirely as _dead code_ * Aggressively optimizes loops, cutting out checks, because it assumes variables won't change on their own This is to make our programs run faster. Compiler employs optimizations, which do not change meaning of correct programs. Reads and writes to regular variables **are not** observability points! --- ### Atomic updates If a value of given length may be atomically updated depends on the hardware! 32-bit X86 CPU does not even have instruction to update 64-bit integer. ```c uint64_t shared_val = 0; // This translates to 2 instructions shared_val = 0x0000000100000001ULL; // mov DWORD PTR shared_val, 1 // mov DWORD PTR shared_val+4, 1 ``` See in [compiler explorer](https://godbolt.org/z/o7fWo8bMx) Fortunately nearly all (**aligned!**) 2, 4, 8 byte accesses on modern hardware are atomic. High-level languages/libraries provide dedicated types and routines to access words atomically, i.e.: ```c atomic_store_explicit(&x, 1, memory_order_relaxed); int ry = atomic_load_explicit(&y, memory_order_relaxed); ``` --- ### Reordering litmus tests Now, let's look at the classic **Store Buffer** test: ```c int x = 0, y = 0; void th1() { x = 1; int r1 = y; } void th2() { y = 1; int r2 = x; } ``` Can this program result in **`r1 == 0` and `r2 == 0`**? On a standard Intel PC? Very often! Both processes think the other did nothing. This is exactly where Peterson breaks down in practice. --- ### Cache Effects Variables do not land in RAM immediately in practice.  * The variable `x = 1` got stuck in a store buffer of a core running `th1()`! * Core executing `th2()` simply does *not see it* yet. --- ### Out-of-Order Execution Even CPU is not a polite, line-by-line instruction executor. It is a massive factory of speculation and pipelining to keep things moving as fast as possible. CPU thinks: > "I can reorder anything, as long as the result is correct from the perspective of THIS SINGLE core."  The hardware disregards by default the existence of other cores reading those same interdependent variables! --- ### Hardware Memory Models Those effects make life of concurrency programmers tough. Hardware providers were eventually forced to describe how memory works on their system and what programs can expect. **x86 (TSO - Total Store Order):** A relatively strong model. Each core has a local buffering queue of memory updates, which is eventually flushed. 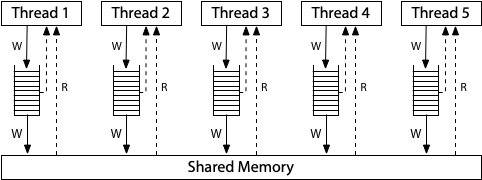 <sub>Source: https://research.swtch.com/hwmm</sub> It allows a Load to be executed before an older Store is finished (Store-Load reordering). --- ### Hardware Memory Models **ARM / POWER (Weak Memory Model):** The Wild West. Here, there is no total store order. 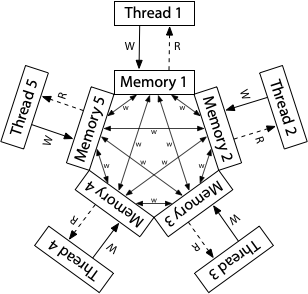 <sub>Source: https://research.swtch.com/hwmm</sub> Code running perfectly fine on x86 often blows up spectacularly on Apple Silicon or a Raspberry Pi. --- ### Memory Barriers To implement algorithms depending on memory ordering CPUs expose specialized instructions called *barriers* or *fences* used to control it. ```asm [1: 2] mov dword [x], 1 ; x = 1 (buffered) mfence ; buffer flush mov eax, dword [y] ; r1 = y ``` Here, the algorithm ensures `x = 1` is visible to all other cores before reading `y`. --- ### The C Memory Model (C11+) Pre-C11: The C language had absolutely no concept of threads or sharing memory. **From C11 onwards:** Any Data Race is officially classified as **Undefined Behavior**. Compilers and libraries provide means of issuing atomic load store instructions and placing memory barriers like so: ```c #include <stdatomic.h> atomic_int x = 0; atomic_int y = 0; void th1() { atomic_store_explicit(&x, 1, memory_order_relaxed); atomic_thread_fence(memory_order_seq_cst); atomic_load_explicit(&y, memory_order_relaxed); } ``` --- ## Part 2 Hardware to the rescue! (leaving Peterson behind) --- ### The Need for Read-Modify-Write Solutions like Peterson's are complex and slow (require multiple instructions). We need help from the CPU. Standard loads (`r = x`) and stores (`x = 1`) are not enough. It'd be best to read a value, modify it, and write it back **in a single, indivisible step**. Modern CPUs provide specialized **Atomic Instructions** to do exactly this. --- ## Atomic Swap It swaps the contents of a register (local variable) with a memory location atomically. ```c int atomic_swap(int *mem, int new_value) { int old = *mem; *mem = new_value; return old; } ``` On X86 all this is done just by a single instrcution: ```asm xchg eax, DWORD PTR mem[rip] ``` --- ### Spinlock using atomic swap We can build our first practical lock: a Spinlock. ```c #include <stdatomic.h> atomic_int mtx = 0; // 0 = free, 1 = taken void lock() { int expected = 1; while (atomic_exchange(&mtx, expected)) { /* busy wait */ } } void unlock() { atomic_store(&mtx, 0); } ``` --- ### Test-and-Set (TAS) Swap with hardcoded `1` as a target value. Writes a `1` to a memory location and returns its **old** value. ```c int test_and_set(int *ptr) { int old_value = *ptr; *ptr = 1; return old_value; } ``` If it returns `0`, you just acquired the lock. If it returns `1`, someone else has it, but you just safely overwrote 1 with 1. --- ### Spinlock using TAS ```c #include <stdatomic.h> atomic_flag mtx = ATOMIC_FLAG_INIT; void lock() { while (atomic_test_and_set(&mtx)) { /* busy wait */ } } void unlock() { atomic_flag_clear(&mtx); } ``` See at [compiler explorer](https://godbolt.org/z/bq1Y97vaP) --- ### Compare-and-Swap (CAS) The undisputed king of atomic operations. It updates this memory location to `new_value`, but only if its current value is equal to `expected_value`. All in one instruction. ```c bool cas(int *ptr, int* expected, int new_val) { if (*ptr == *expected) { *ptr = new_val; return true; } *expected = *ptr; return false; } ``` x86 provides the `CMPXCHG` instruction doing exactly that. While for spinlock simple TAS is enough, CAS allows for implementing more complex concurrent algorithms. --- ### Evaluating Spinlocks 1. **Mutual Exclusion**: Yes, thanks to hardware guaranteed atomicity. 2. **Progress**: Yes. If the lock is free, the next atomic operation grabs it. 3. **Bounded Waiting**: NO! Spinlocks offer no fairness. A fast thread can release and re-acquire the lock before a waiting thread's atomic instruction executes. Spinlocks have another major flaw - **busy waiting**. If thread A holds the lock for a longer time (possibly gets preempted by the OS scheduler), thread B will burn 100% of its CPU timeslice just checking. This is a massive waste of energy and CPU cycles. --- ## Part 3 From Spinning to Sleeping --- ### Semaphores (1965) Invented by Edsger Dijkstra, a Semaphore is an OS-level synchronization primitive. It consists of two parts: - an integer counter - a waiting queue (managed by the OS scheduler) ```c typedef struct { int value; struct task* waiters; } semaphore; ``` Instead of spinning, processes block (go to sleep), making CPU available to others. --- ### Semaphore Operations Historically named after Dutch terms<br> _Proberen_ (to test/wait) and _Verhogen_ (to increment/signal) - `wait()` / `P()` / `down()`: decrements the counter. If the counter drops below 0, the OS suspends the thread and puts it in the wait queue - `post()` / `V()` / `up()`: Increments the counter. If the counter is still negative then someone is waiting. The OS wakes up one thread from the queue. --- ### Semaphore Implementation ```c void wait(semaphore *S) { S->value--; if (S->value < 0) { queue_push(&S->waiters, ACTIVE_TASK); sched_block(); } } ``` Implementation must guarantee that no two processes can execute `wait()` and `signal()` on the same semaphore concurrently. Thus, the implementation becomes the critical section problem in itself. Here however, in the OS code, busy-waiting solution is perfect. The code within CS is short and fully under OS control. --- ```c void wait(semaphore *S) { lock(&S->lock); S->value--; if (S->value < 0) { queue_push(&S->waiters, ACTIVE_TASK); sched_block(); } unlock(&S->lock); } ``` ```c void signal(semaphore *S) { lock(&S->lock); S->value++; if (S->value <= 0) { struct task* P = queue_pop(S->waiters); sched_wakeup(P); } unlock(&S->lock); } ``` --- ### Semaphore inefficiencies Semaphores solve the CPU burning problem! But they introduce a new one: system call overhead. `wait()` and `post()` must be syscalls. Each time process wants to synchronize it must switch into the kernel mode, even if the critical section is free. If the lock is completely free (uncontended), trapping into the kernel just to decrement a counter from 1 to 0 is thousands of times slower than a simple userspace atomic operation. --- ### The Holy Grail: Linux Futex (2002) _Fast userspace mutex_ Modern hybrid solution: - Speed of hardware atomics when the lock is free. - Sleeping capability of the OS when the lock is taken. Futex combines the best of both worlds. It is the bedrock of `pthread_mutex_t`, `std::mutex` and all other library synchronization primitives. --- ### How Futex Works A futex is simply a standard 32-bit integer in a shared userspace memory. Kernel maintains a waitlist associated with futex address. ```c #include <linux/futex.h> #include <sys/syscall.h> #include <unistd.h> uint32_t ftx; // A 32-bit futex // Linux syscall long syscall(SYS_futex, uint32_t *uaddr, int op, ...); ``` Applications may use the 32-bit word to synchronize using hardware atomic instructions, i.e. CAS. Only if a thread fails to acquire the lock and needs to block it calls into the syscall. --- ### Futex mutex The `futex()` syscall operates differently depending on `op` parameter: - `FUTEX_WAIT` blocks calling process (adds it to the associated waitlist) - `FUTEX_WAKE` wakes up blocked threads (pops from waitlist) Kernel implementation compares futex value to what calling thread believed it to be before making calling into the OS. The Syscall fast-fails on mismatch. ```c futex(&ftx, FUTEX_WAIT, /*expected*/2); ``` From `man 2 futex`: > "The loading of the futex word's value, the comparison of that value with the expected value, and the actual blocking will happen atomically [...]" --- ### Simplified mutex implementation ```c++ void simple_lock(simple_mutex_t *m) { while (atomic_exchange(&m->state, 1) != 0) { // Fast lock failed, need to wait // Sleep, but if and ONLY if the state is still 1 futex(&m->state, FUTEX_WAIT, 1); } } void simple_unlock(simple_mutex_t *m) { atomic_store(&m->state, 0); // Wake possible waiter futex(&m->state, FUTEX_WAKE, 1); } ``` ---  Note that despite CS in the kernel side `ftx` word may be changed by other cores at any time! `simple_unlock()` unconditionally calls `FUTEX_WAKE` to deal with such situations. --- ### Lock() implementation Simple version calls `FUTEX_WAKE` unconditionally so it does not take full advantage of syscall-free fast paths. In fully-grown implementation the futex word has 3 states:<br>free (`0`), locked (`1`) and locked with possible waiters (`2`). ```c int expected = 0; if (atomic_compare_exchange(&ftx, &expected, 1)) { return; // Locked first! No syscall! } while (1) { if (atomic_exchange(&ftx, 2) != 0) { futex(&ftx, FUTEX_WAIT, 2); } else { return; } } ``` --- ### Unlock() implementation ```c void unlock(futex_mutex_t *m) { if (atomic_fetch_sub(&m->state, 1) == 1) { return; // We were the only one! } // There could be waiters (state was 2) atomic_store(&m->state, 0); // Wakeup at most 1 thread futex(&m->state, FUTEX_WAKE, 1); } ``` --- ### THE END